Text Warrior中一些不足之处
前言
不少Android项目中,都使用了Text Warrior作为它们的代码编辑器。这个项目的视图是直接继承自View的,与那些继承TextView、EditText的项目不同。使用TextView,我们虽然能够获得较为出色的显示效果,但是在文本较长的时候,会造成卡顿阻碍用户输入,因为我们不得不在主线程中更新我们的Spans,而且每更新一个Span,都会导致TextView重绘。而且经常因为正则表达式不够准确而导致高亮出错。
TextWarrior则没有此问题。它收到文本更新的时候,会调用其他线程启动Lexer来刷新高亮,在该线程结束之后刷新绘制,这既保证了高亮的正确性,也保证了UI线程的流畅。然而,它其中有一些不足之处导致大文本仍然不能较快地显示,以及一些用户体验的问题。
绘制问题
Span查找问题
TextWarrior的Span是用ArrayList,依照顺序依次存起来的,Span中保存了它的Start Index。利用有序的性质,我们可以很快地利用二分将特定Index对应的Span找出来。尤其是在绘制时,这十分有用,直接将O(N)复杂的降到O(log N),很快。但是,目前在各处流传的版本都是按照顺序对Span进行查找的,这是realDraw()中关于查找的一段代码
1 | //---------------------------------------------- |
我们看到,它用了顺序查找,检查Span的Index有没有达到起始绘制的Index。
这在显示大文本的后端的时候,会造成卡顿。
解决办法是用Binary Search。
绘制提交问题
TextWarrior除了在查找Span有性能障碍意外,绘制也有问题.
先来分析一下下面这个代码啊:
1 | //---------------------------------------------- |
我们一看这个绘制,还行吧,游标什么的的绘制都合并到一起去了,换行的时候才更新baseline,节约了不少测量提交啊,不错不错.
但是我们看到,它是一个一个字符绘制的!!!
我们再看看drawChar:
1 | private int drawChar(Canvas canvas, char c, int paintX, int paintY){ |
我:???
我们看到,每绘制一个字符,都创建一个char[].好兄弟你就不能把它缓存起来吗!!!绘制的时候要尤其注意,尽量少创建新对象,这会拖慢绘制的速度.
还有一个什么问题? 嗯,虽然在Java中,一个char能表示的字符有很多,但是也不是全部都能表示.不能就不能吧,那些不能一个char表示的字符用的也不多.但是我们有一个很常见的符号表:emoji!
Emoji都是两个char组成的! 这就会导致在绘制中,emoji会变成一个菱形包裹的’?’
再看看getAdvance():
1 | protected int getAdvance(char c){ |
嗯,和drawChar()差不多的原理. 但是我们发现,这些getAdvance(),返回类型都是int!
这会导致在低DPI设备上字体较小时,空格和tab无法正常显示(advance = 0),所有的字符看起来都是连在一起的.
此外,一个一个char绘制,需要提交的measure/draw的次数较多,在native似乎没有对字符宽度进行缓存.
而且,这样频繁提交measure/draw会消耗很多时间,从而造成卡顿.
我建议的方式按行绘制,然后依照行里面的Spans进行区间绘制,可以减少这一损耗.
此外,针对字符measure的结果可以使用SparseIntArray或者直接开float[]保存起来,这样实测比总是向native提交measure快大约10倍
如下图所示:

读入的文件是我的CodeEditor.java,长达118KB,我将回车删去了只有一行.
在直接将整个文件内容给native测量,10次花费了9157ms.而使用SparseIntArray缓存字符大小,10次只用了979ms,可见差距有多大.
也告诉我们不是所有的操作在native就更快了,比如像这样的字符测量,在native很有可能没有缓存,每次遇到之前遇到的字符也要和之前一样处理,从而导致速度降低.也影响了我们的绘制过程.
这里还有一张区块绘制与逐字符绘制的对比图: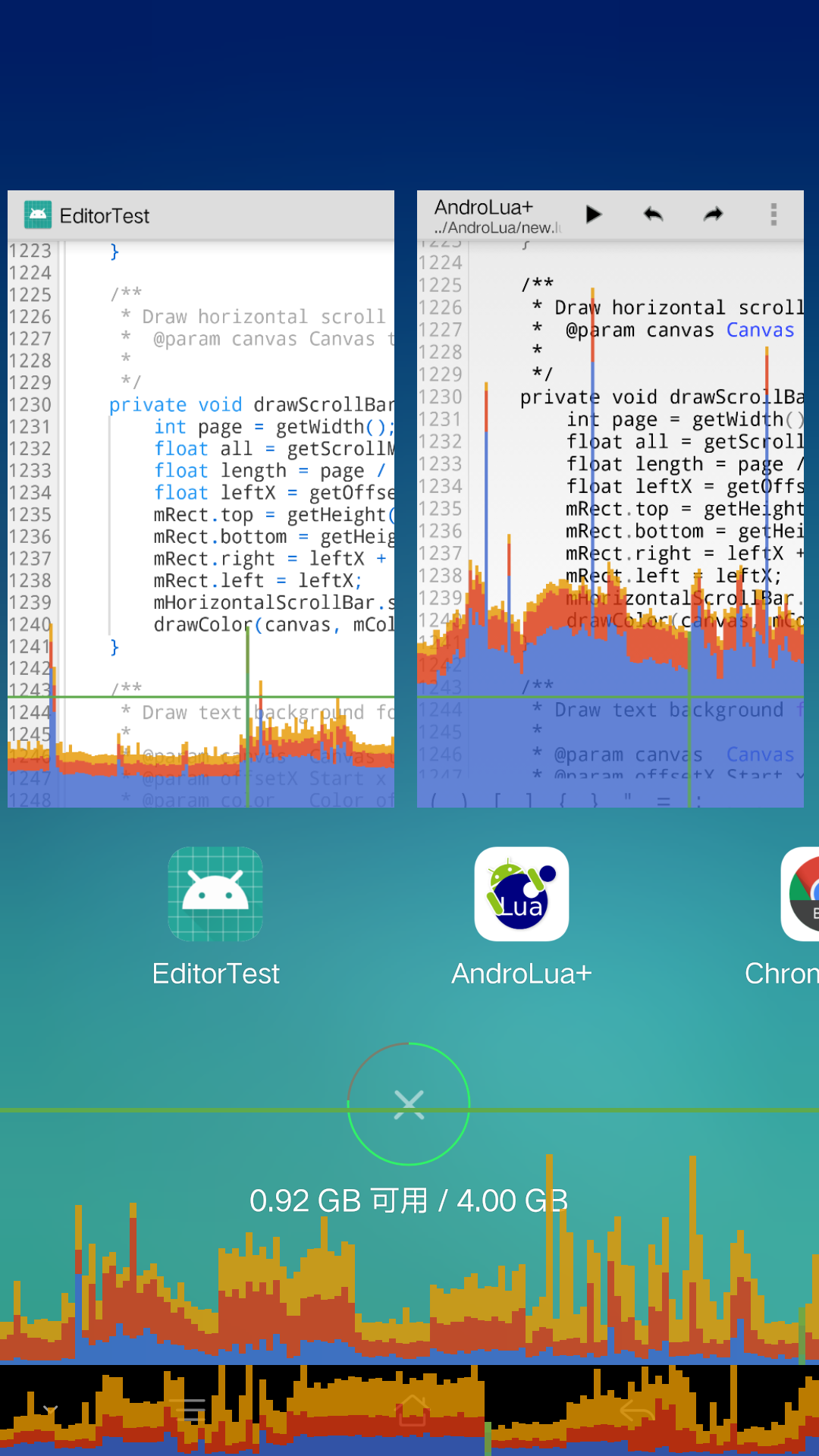
可见其速度差异.
此外我们还发现一个问题:只要这一行是可见的, 那么这一行的所有字符都会被提交绘制!无论这个字符在这一行上是否对用户是可见的,都会被绘制! 这又是一个性能问题. 如果说这是为了后面更新最大横向绘制位置的话,我们完全可以用一次measureText完成,至少前部的不可见部分是不用绘制的.
用户体验问题
高亮非法时的显示问题
TextWarrior在文本编辑之后,高亮还没有分析完毕时,绘制出的高亮由于Spans没有被维护,会导致高亮区域错乱.
要命的是,有的时候你能观察到明显的文本闪烁现象,也是Spans没有被维护造成的.
而且若要按目前的方案实现这一维护,也是消耗性能的,可能导致文本输入卡顿.因为输入/删除一个字符意味着后面所有的Spans的Index都必须被更新,才能达到维护的目的.这在Span较多时会耗费较多时间.
在这一点上做出改进的AndroLua+的方案可以减少损耗,它Span中保存的不是Start Index而是Length,从而能在较少时间内维护好Span的范围.遗憾的是这不能使用二分进行加速处理,查找Span依然需要时间.
横向滚动最大值
前面提到TextWarrior会更新横向绘制的最大值,原因在于它使用这个值来确定最大横向滑动位置.如果有更长的行,它还没有被滑动到,那么此时的最大横向滑动位置是无法让那一行显示全的.而用户在滑动过程中,由于惯性滑动,突然横向最大距离发生了增大,那么惯性滑动很可能就导致视图偏移过去了. 而且,在最长行变短之后,糟糕的事情发生了:最大值不会更新,导致过度的横向滑动可以产生,如果改动较大,那么用户甚至可以看到一堆白屏.
输入法信息
1 | //********************************************************************* |
我们看到一句什么话? “不提供提取文本相关的方法”
咱们用起这个编辑器来感觉好像没什么问题.然而,输入符号对的时候,我们惊讶地发现,游标自动跑到最前面了!
原来,输入法依赖getExtractedText主动获取光标在文中的位置,然后再通过setSelection设置游标.如果不实现这个方法,那么输入法就会认为文本长度为0而通过setSelection把光标设定到0了!
同时搜狗输入法在向编辑器发送KeyEvent的KEYCODE_DPAD_LEFT或者KEYCODE_DPAD_RIGHT之前会先通过getExtractedText来获得编辑器中的文本,以确定是否可以向左/向右移动光标,如果不能,那么它不会执行任何操作.
另外,如果使用过大屏幕设备的用户可能会发现,启用像电脑上一样会跟随的输入法条,TextWarrior会让它”不知道跑到哪里去”.原因是编辑器没有调用InputMethodManager的updateCursor或者updateCursorAnchor来更新游标在应用窗口中的位置.
高亮分析问题
上面已经说过,TextWarrior会在另一个线程中分析高亮.文本更新的时候,FreeScrollingTextField调用Lexer#tokenize()来异步运行lexer. 严格来说,这已经不属于TextWarrior本身的问题,而属于后续修改者的问题. 我们经常使用 JFlex 来构建词法分析器,这些修改者并没有做得很好. 在原TextWarrior中,词法分析的循环是这么写的:
1 | while (hDoc.hasNext() && !_abort.isSet()){ |
_abort正是tokenize发现线程正在运行的时候设立的停止flag, 这些JFlex使用者们并没有利用到这一flag来及时停止操作,从而导致时间上的浪费.在分析稍大文本时,时间浪费尤其明显.
TextWarrior原版也有问题:存储Spans没有用ArrayList,而是使用的各种方法都用synchronized标注的Vector,而tokens是只被单个线程操作的,没有必要使用线程安全的类,导致性能下降.
其它
TextWarrior中也有一些源码上的命名很怪,比如Yoyo,一开始见到它的时候不知道是什么东西,仔细一看才知道是选择手柄.