Python 性能分析:大幅提升 ragas 评测运行速度
ragas 是一个用于 RAG 的评测框架,能够使用 LLM-as-a-judge 的方法系统性地验证 RAG 系统检索、生成效果的评测指标。
尽管从 ragas 仓库的数据看上去有很多人使用,但是笔者在实际使用的时候发现其并发量较差。
由于最近毕设 deadline 将近,笔者急需获取毕设中 RAG 系统的 performance metrics 以编写论文,故在 ragas 运行同时检视其性能瓶颈(反正盯着屏幕也没什么别的事做)。
我想 profile 它的缘由
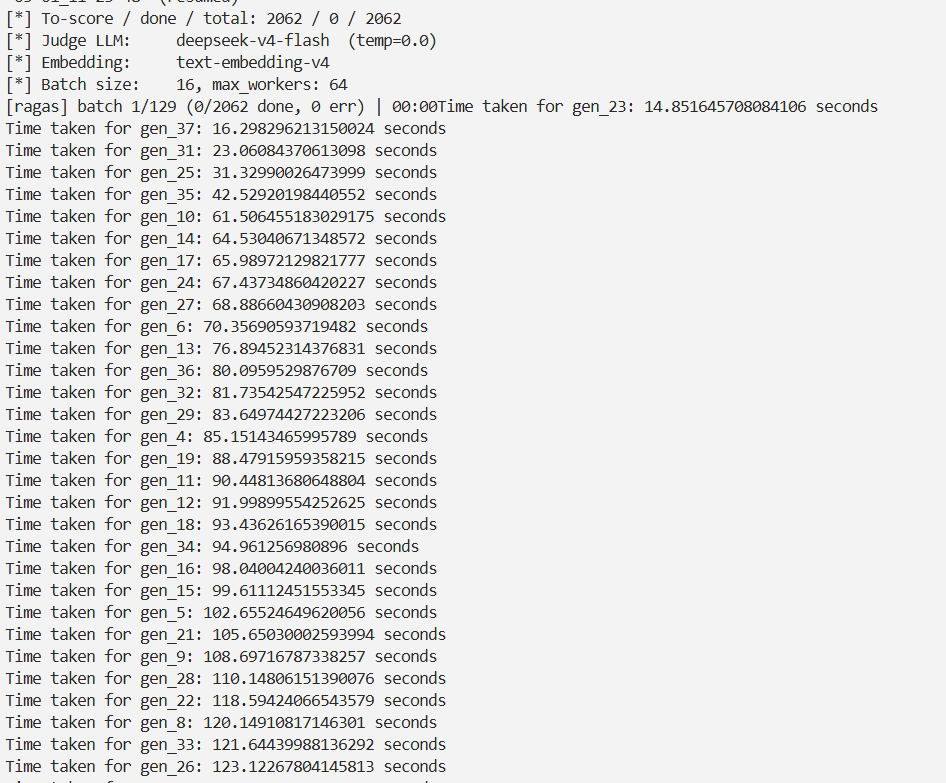
我给 ragas 的运行配置设置了 64 workers 的并发,每 16 个问题为一个批次进行单轮对话数据的相关指标计算。正常来说,这个级别的数据应该几分钟内可以出一个批次的结果。但是我实际跑一个批次不但等了好几分钟都没有出结果,甚至出现大量网络请求超时,导致相关指标无法计算,这让我非常不解。
于是我直接查看和修改 ragas 源码,跟踪我传入的 LLM API Client,找到主要 LLM 对话入口点 埋了耗时记录:
1 | async def generate( |
这里是调用 LLM 进行单次生成,如果正常的话,应该几秒就能得到结果。可实际情况令人大跌眼镜:前几个请求确实很快就返回了结果,但后面的请求时间越来越长,高达分钟级,后面甚至直接超时。
考虑到先前笔者编写的 RAG pipeline 中阿里云 LLM API 的生成速度、并发量都较为可观,而且后台数据的请求时间确实也很短,故怀疑请求速度慢是 ragas 框架本身所致,于是开始 profile。
使用 py-spy 监测性能
py-spy 能够对运行中的 Python 程序进行性能采样,主要是查看各线程当前的活动并统计函数活动时间占比。
只需要安装 py-spy 就可以直接通过命令行调用:
1 | pip install py-spy |
我们拿到 Python 的 PID,看一下活动 top:
1 | py-spy top --pid <PID> |
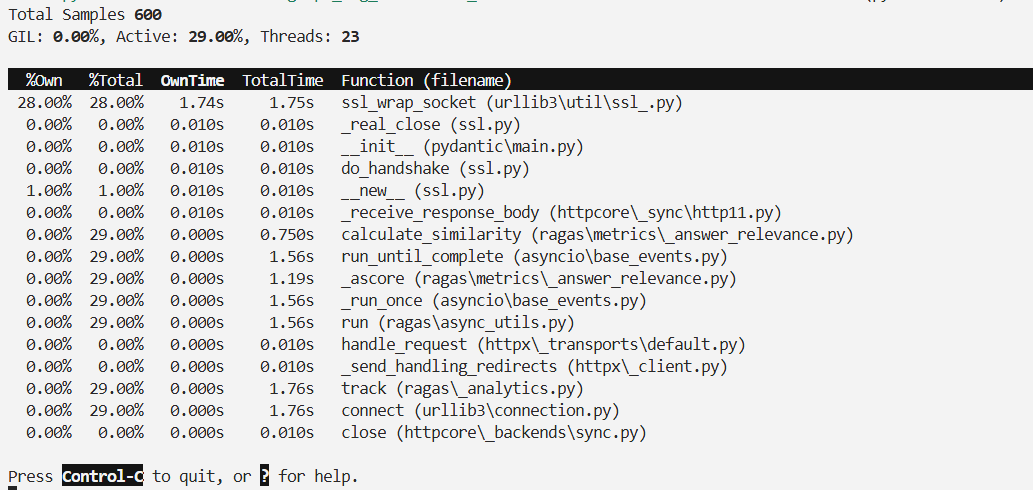
看起来似乎很正常,我们调用远程 API 确实需要连接 socket,所以这个函数占用时间也比较正常。
笔者常年科学上网,难道是我的 TUN 代理服务存在影响?但是关闭 TUN 等代理服务后,重新跑 ragas 问题依旧,说明问题不在这。
问题 1: 同步发送的使用跟踪情况
排查系统环境无果,继续使用 py-spy 的 dump 功能查看目前每个线程在做什么:
1 | py-spy dump --pid <PID> |
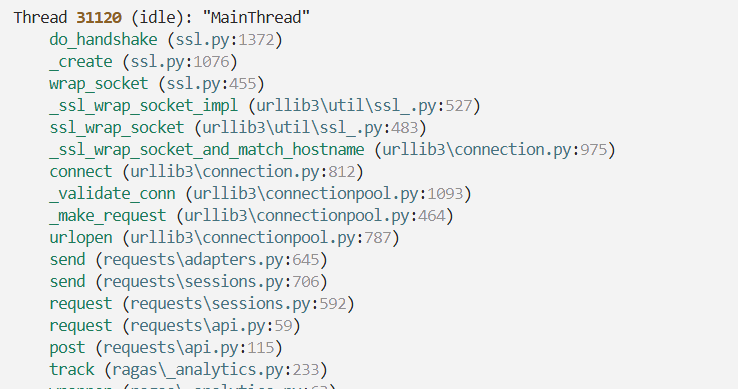
这里 MainThread 在一个未曾预料的路径上:_analytics.py:233 一个名为 track 的函数正在发同步的网络请求 requests.post:
1 |
|
一看,神 TM 的使用跟踪函数,而且是默认开启的。查看函数 References 发现它在多个函数中均有调用,有些没有定义成异步函数,因此这个 track 也没有定义成异步。
ragas 的 evaluation 的过程环境是异步的。在异步环境中使用同步网络请求是大忌,这会导致整个事件循环被该网络请求阻塞(通常,除了指定到 Executor 中执行的任务,其他任务均通过事件循环在主线程中执行)。如果必须发送网络请求,应该使用异步网络请求或者将该请求转移到 Executor 中执行。
因此这里直接在 track 函数 return,不发送使用数据即可。
问题 2: 写到一半丢了异步的 metric 计算
解决前述问题后,速度有所提升,但仍非常缓慢。继续使用 dump 查看线程堆栈,发现 MainThread 又落在了 httpx 的路径上。

跟踪代码,发现是 _answer_relevance.py:calculate_similarity 在调用我们传入的 Embedding 对象计算嵌入。
查看源码,非常可笑:分数计算的入口是 _ascore,该函数调用自己的 _calculate_score 时就丢去了 async,然后走到 calculate_simularity,需要通过网络请求计算 embedding 了,又把主线程堵住了。
1 |
|
这里直接把两个 calculate_* 函数改造为异步,然后把两个 embedding 调用通过 asyncio.to_thread 派遣到 executor 中执行再即可。因为笔者的 embedding 模型的相关代码并没有用异步网络框架,就不切到异步函数上了。
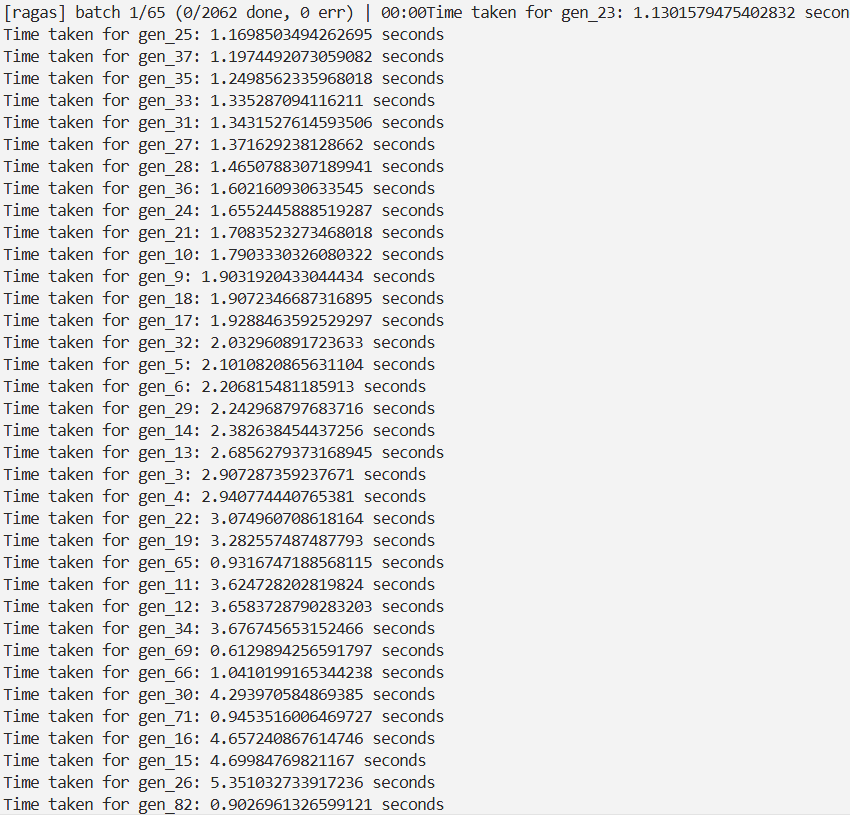
修复上面两个问题后,重新开始 ragas 评估,就很顺畅了,在不触及 API 的 请求速率限制情况下,仅需一分钟即可完成一批 16 个问题在 7 个指标上的评估,提升非常可观。MainThread 也不再出现同步的 I/O 操作。
问题 3: 线程池大小
由于笔者的 embedding 计算函数是同步的(为了在 RAG pipeline 中兼容 ChromaDB),所以只能派遣到线程池执行,默认情况下该线程池的大小为 min(32, CPU核心数+4),所以只能同时处理最多 20 个请求(笔者的电脑为 16 逻辑处理器)。这个请求速度还无法达到笔者使用的 Embedding API 速率限制上限。要榨干 API 的 RPM 和 TPM,必须提升线程池容量。
我们需要将 evaluate 的调用切到 aevaluate 的异步函数路径,然后将自己的调用处包一层异步函数以修改 Executor:
1 | from concurrent.futures import ThreadPoolExecutor |
改进完成后,我们再测试一下一个批次所需的时间,在不触及 API Rate Limit 的情况下,时间又缩短了数秒:

总结
ragas 运行缓慢主要是在主线程发送统计数据导致的,取消发送统计数据之后速度已经有了相当可观的提升。为了进一步提升评测的速度,我们找出了其他在主线程发送同步网络请求的函数,并迁移到 executor 执行。此外,还扩容了 executor 的线程池大小,能够同时容纳更多的网络 I/O 操作。最终极大地加速了整个评测流程。
asyncio 框架的本意就是通过异步 I/O 操作提升 Python 的运行效率。其 I/O 操作主要通过 select/poll/epoll 的方式高效进行。当一个 task 因 I/O 操作等待时,可以执行其他 task. 在主线程上使用同步 I/O 会导致线程被该同步 I/O 操作阻塞,导致失去该优势,退化为普通单线程程序。